The rise of data contracts is a path to data maturity
Data contracts… If you would place them on the hype cycle, they still might sit before the peak of inflated expectations. Yet in the software engineering industry, data contracts have existed already for decades, called API contracts. Finally data contracts, like many other software engineering best-practices, are coming to data and they are here to stay.
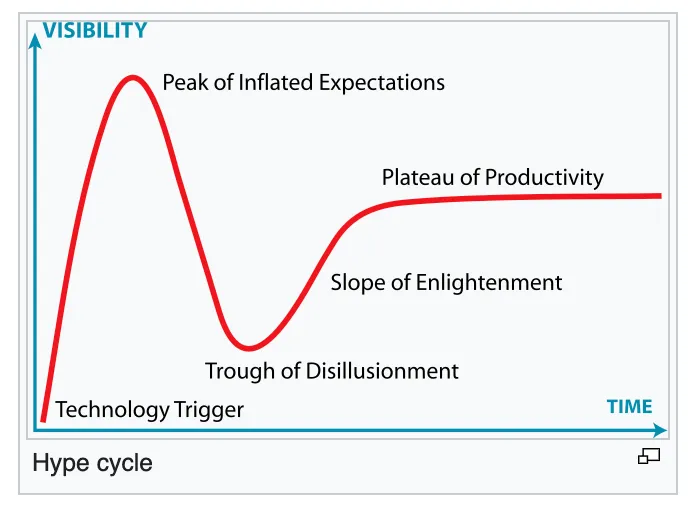
Gartner hypecylce — image of Wikipedia
But what is a data contract? What are they trying to solve, what does it contain, how do you enforce them, where do you create them and how do you make the information searchable, …? Too many content out there, is vendor driven content. Which means that it is heavily colored with the vendors back ground. We, Karin Hakansson, Amy Raygada, Andrew Sharp and myself, have discussed these, and even other questions together with our participants on the data mesh learning roundtable on data contracts.
What are data contracts
Why are data contracts emerging? Some say they foster data quality, data ownership, transparency, efficiency and process engineering. This is quite a lot and tells nothing at the same time. In short, data contracts have been introduced to stabilize data pipelines. It’s a mutual agreement between a producer and consumer on what data is expected. These expectations can concern the actual what, or your data schema, but also the quality of data, think of missing data, unique values, latency, and more. The contract aims to reassure data consumers to consume the data without hesitance.
As mentioned, many content on data contracts is vendor driven, which result in different key elements of the data contract:
- Data catalogs offering a data contract template, often stress the data schema (most often captured as a JSON schema) and data owner metadata
- Data quality tools offering a data contract template, mostly focus on quality measurements and the SLO’s and SLA’s attached to those
- Data access management solutions on the other hand try to include access management policies
- Close to all of them, include some kind of notification system, but we will go deeper into this topic later.
Start with a schematic representation — Photo by Hal Gatewood on Unsplash
We believe that most of these elements can be included in a data contract, depending on the goals you have as an organization. Starting with a data schema is a no-brainer. As a data contract should be created and maintained by the data producer, preferably agreed upon by all consumers, it should also contain metadata about this producer to allow you to contact him or her.
A large element of using data without a doubt, is knowing what the data is about. Therefor data should be self-describing, or as an alternative, the data contract should provide sufficient context to the data true well-defined descriptions. Data quality is the second element of trustworthy data. This part of the contract can vary quite a lot: it can contain basic elements as unique values up until complex quality measures. Latency or recency and data retention policies are closely linked to this topic and should be included as well. With respect to access, we certainly foresee the purpose of the data product being registered in its contract, but not necessarily more access related items. This heavily depends on the way data access is organized or implemented in the organization.
Data contracts and data products
I did mention that a data contract should hold the purpose of the data product it describes. This has triggered a linguistic discussion during the round table. Just like an API having multiple endpoints, a data product can have multiple output ports. As an example, think of a masked and unmasked version of the data, or the same data filtered on region. The purpose resided on the level of the output port, not of the data product. Which means that the contract as well resides on the level of the output port.

Data product output ports — Photo by Steve Johnson on Unsplash
Getting data contracts in place, becomes much harder when you are dealing with external data producers. At first sight, this seems logical, yet it actually contradicts software engineering best-practices. Think about your organization using Salesforce: Salesforce offers API’s to integrate the tool in your IT architecture and does not allow you to bypass these, but with respect to data, no data contracts exists and you should extract data directly from the source. With data contracts becoming more and more mature, we will probably see the adoption of data contracts for external vendors as well, but we are not yet there.
Do you enforce data contracts?
A short answer: yes. Or at least as of a certain moment. There is a natural process of installing and adopting data contracts:
- Documentation: move typical confluence documentation closer to your data, to code, which will be the initialization of your data contract
- Notification: warn when a contract has been violated
- Enforcement: truly enforce the contract, preferably at deploy time
Let’s start with discussing the enforcement. We advice against blocking at write time: when data at write time gets blocked, this might introduce other data contract violations as well: think about latency or recency. Therefor we believe that with regards to data quality issues being detected, you should have a notification system in place, but with regards to data schema changes, you should prevent changes being published without revision. Pull request reviews by data consumers make sense. This will also force you into thinking about change management when altering the data contract: temporarily having two versions while deprecating the old one over time.

Install pull request reviews, all need to agree — Photo by Vidar Nordli-Mathisen on Unsplash
In some industries, these pull request might not even be sufficient and someone like a DPO also needs to sign of on the contract, making it close to legally binding. In pharma, banking, or insurance, this might help to validate compliance with regulatory requirements like data protection.
Remark that as a first step, we already see a lot of value in moving documentation to code. This helps data engineers as they have less tools to use, enforces everything in a similar format and speeds up the actual implementation of data contracts later on.
Where to find contractual information?
Data contract metadata can be visualized in data catalogs. Other tools, like data quality tools, data product portals, data engineering workbenches, and many more are including the same visualization. Every tool that has a data object overview, or the subset of data objects that are shared throughout the organization, can visualize the contract.
We see data contracts mostly rising in the analytical data space, describing your data mesh or more in general your data products. This again indicates that the above mentioned tools are the correct place to include the visualization. There is just a single element that deviates from most of these tools: the concept of stakeholders. Most of these tools start from data owners, something difficult to assign as we had discussed in the previous round tabel. With data contracts, we see the need for a more broad concept of stakeholders:
- Business owner: he or she owns the purpose of data
- Lead data engineer: the person you call when something goes wrong
- Data governance team: those people that might need to sign off
- Data architect: someone who keeps the global overview
Note that we deliberately have not included the data consumers as a stakeholder.
What’s next?
Data contracts are here to stay. Templates on what needs to be included, will most likely converge and maybe extend data schema and data quality SLO’s and SLA’s. External tools might offer data contracts, just like API contracts as well. We foresee mostly a pull request based review policy, which prevents unreviewed changes to hit production. But the biggest challenge we foresee, is how to visualize the captured information. This will have an impact on the data catalog space, and might emerge a consolidation with the data quality space.

Round table on data domains — Image by Data Mesh Learning community
And for us? Well, next round table we will discuss data domains. Register via meetup and see you there!